The conventional wisdom, well captured recently by Ethan Mollick, is that LLMs are advancing exponentially. A few days ago, in very popular blog post, Mollick claimed that “the current best estimates of the rate of improvement in Large Language models show capabilities doubling every 5 to 14 months”:

I’d like to read the research you alluded to. What research specifically did you have in mind?
Sure: here’s the article.
https://arxiv.org/abs/2304.15004
The basics are that:
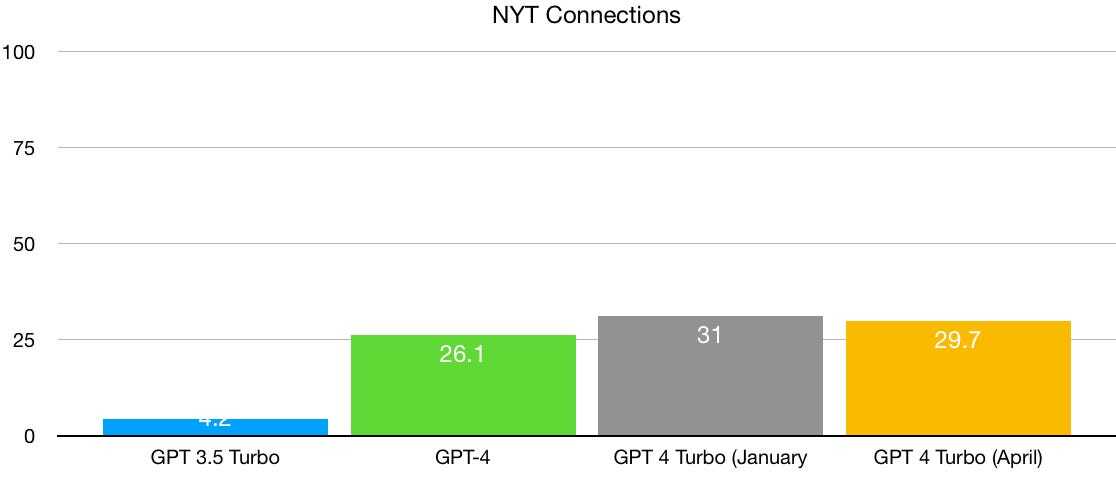
LLM “emergent behavior” has never been consistent, it has always been specific to some types of testing. Like taking the SAT saw emergent behavior when it got above a certain number of parameters because it went from missing most questions to missing fewer.
They looked at the emergent behavior of the LLM compared to all the other ways it only grew linearly and found a pattern: emergence was only being displayed in nonlinear metrics. If your metric didn’t have a smooth t transition between wrong, less wrong, sorta right, and right then the LLM would appear emergent without actually being so.