Stephen Wolfram explores minimal models and their visualizations, aiming to explain the underneath functionality of neural nets and ultimately machine learning.
They have a fixed number of interconnected nodes that encode the data via the weights between them.
So processing requirements are the same. Training is where a lot of power goes though.
This also gives it the ability to solve things we don’t have an equation for. As long as we know the input and output we can train an NN to do the calculations even if we don’t know the equation ourselves.
The black box nature is a problem but that’s also where it’s power comes from.


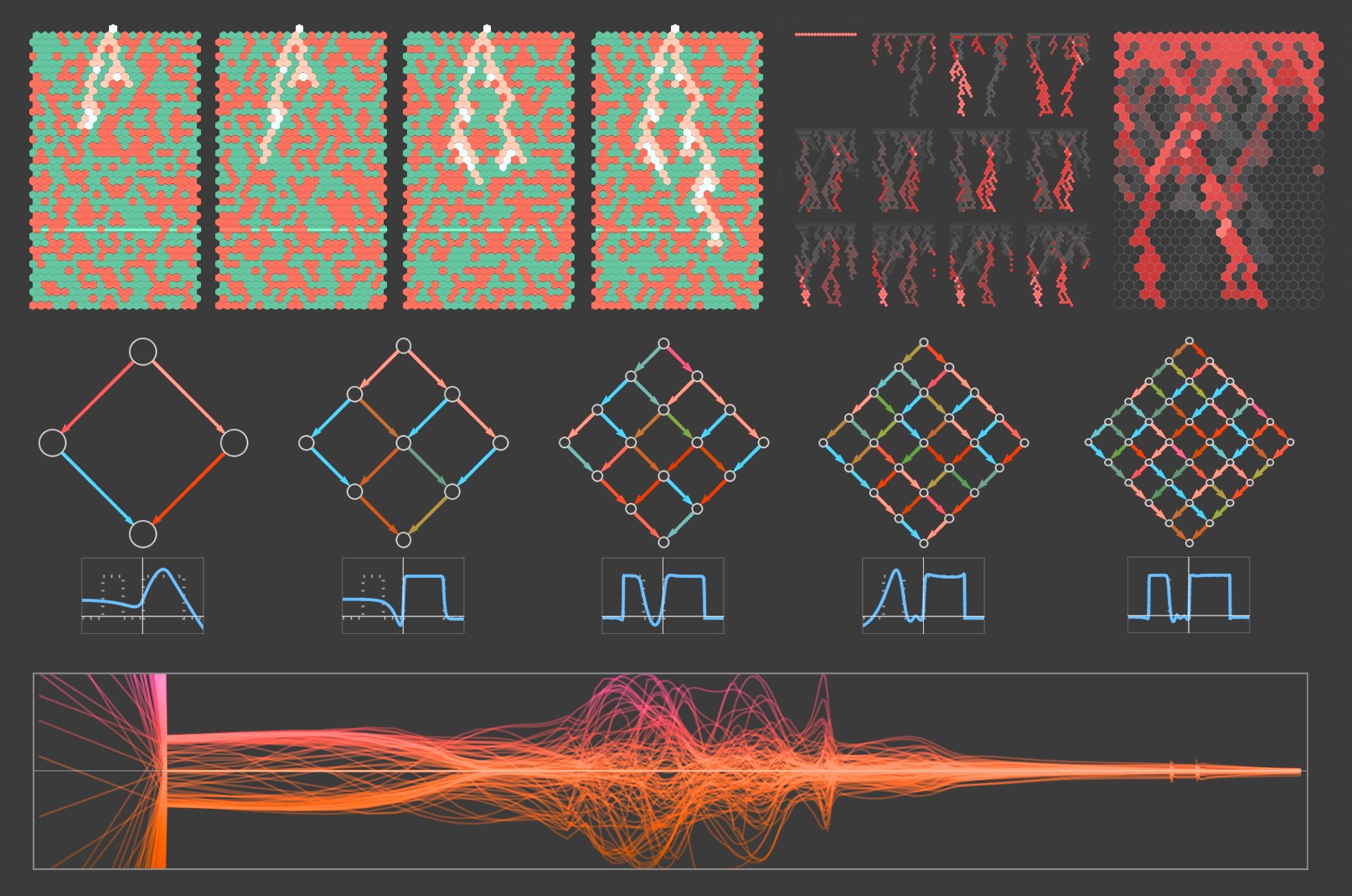
More data doesn’t mean more processing.
They have a fixed number of interconnected nodes that encode the data via the weights between them.
So processing requirements are the same. Training is where a lot of power goes though.
This also gives it the ability to solve things we don’t have an equation for. As long as we know the input and output we can train an NN to do the calculations even if we don’t know the equation ourselves.
The black box nature is a problem but that’s also where it’s power comes from.